Problem
Geodata aggregation, clipping, and preparation is one of the biggest time sinks in urban planning projects. Data is scattered across multiple geoportals, APIs, and formats. Even for technically proficient analysts, harmonizing datasets into a usable format takes hours. For non-technical stakeholders in city administration, it is often impossible without GIS support.
Solution
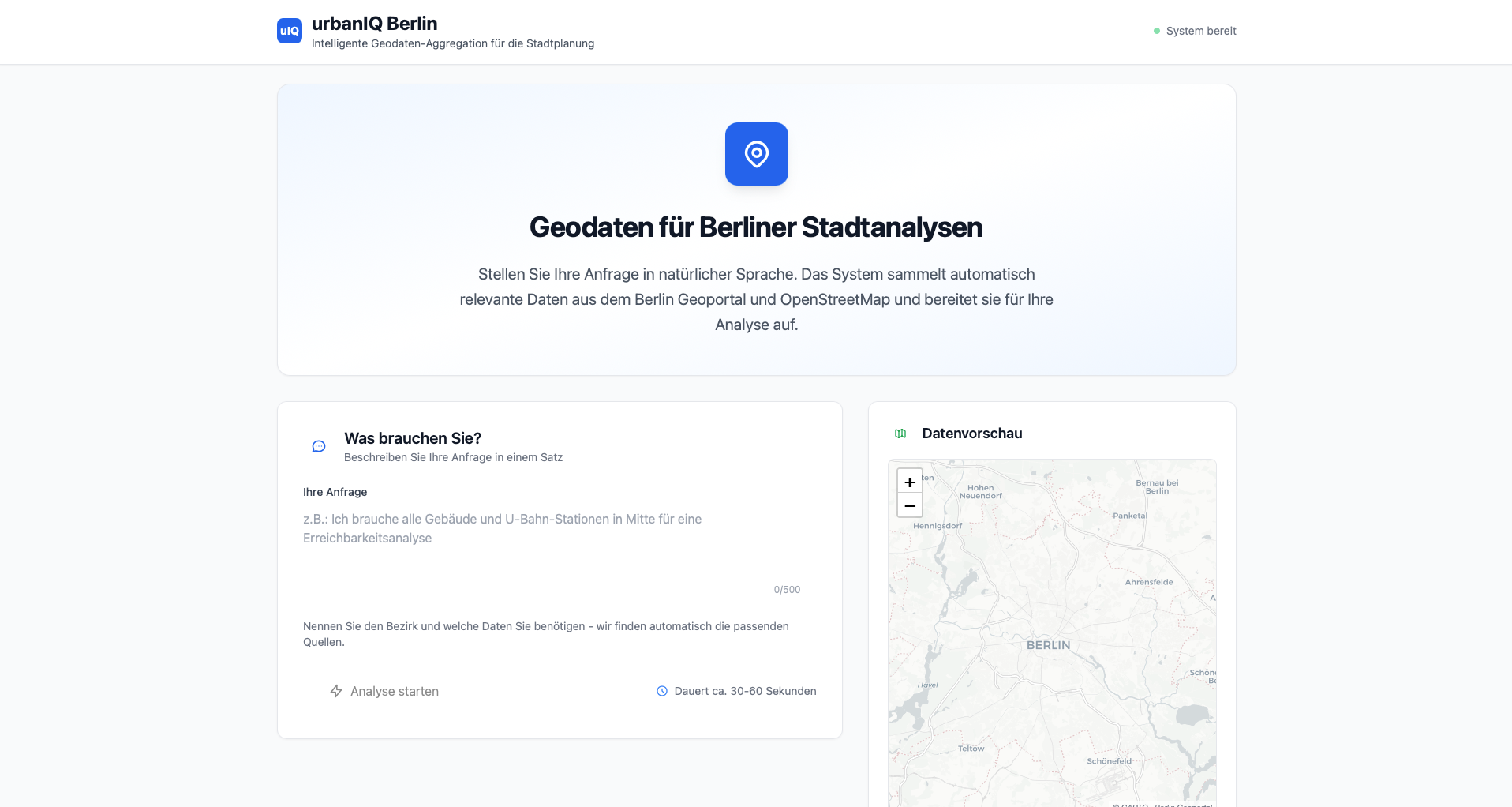
A geodata aggregation system that accepts natural-language queries, identifies relevant data sources, retrieves and clips data to the requested spatial level, harmonizes formats and CRS, and outputs unified geodata packages with metadata reports. Web interface for non-technical users.
Result
Accepts a natural-language query and returns a harmonized geodata package with metadata documentation. Shows that LLM-based query parsing with automated geodata pipelines reduces the manual effort in urban planning data preparation.
Technical Details
Four-stage pipeline. NLP layer parses natural-language requests via OpenAI GPT to identify required datasets and spatial levels. Data retrieval orchestrates downloads from Berlin Geoportal WFS and OpenStreetMap Overpass API. Spatial processing handles CRS transformation, clipping, and schema normalization via GeoPandas. A metadata module generates reports on data quality and usage guidance. Built with FastAPI and HTMX.